road-of-leetcode
0173. 二叉搜索树迭代器
这个题真的是有点尴尬.
不动态改变树结构的话, 初始化的时候中序遍历一遍把结果存下来就 ok 了, 算是 easy 难度.
动态改变树结构的话, 这题就应该归类到 hard 难度了.
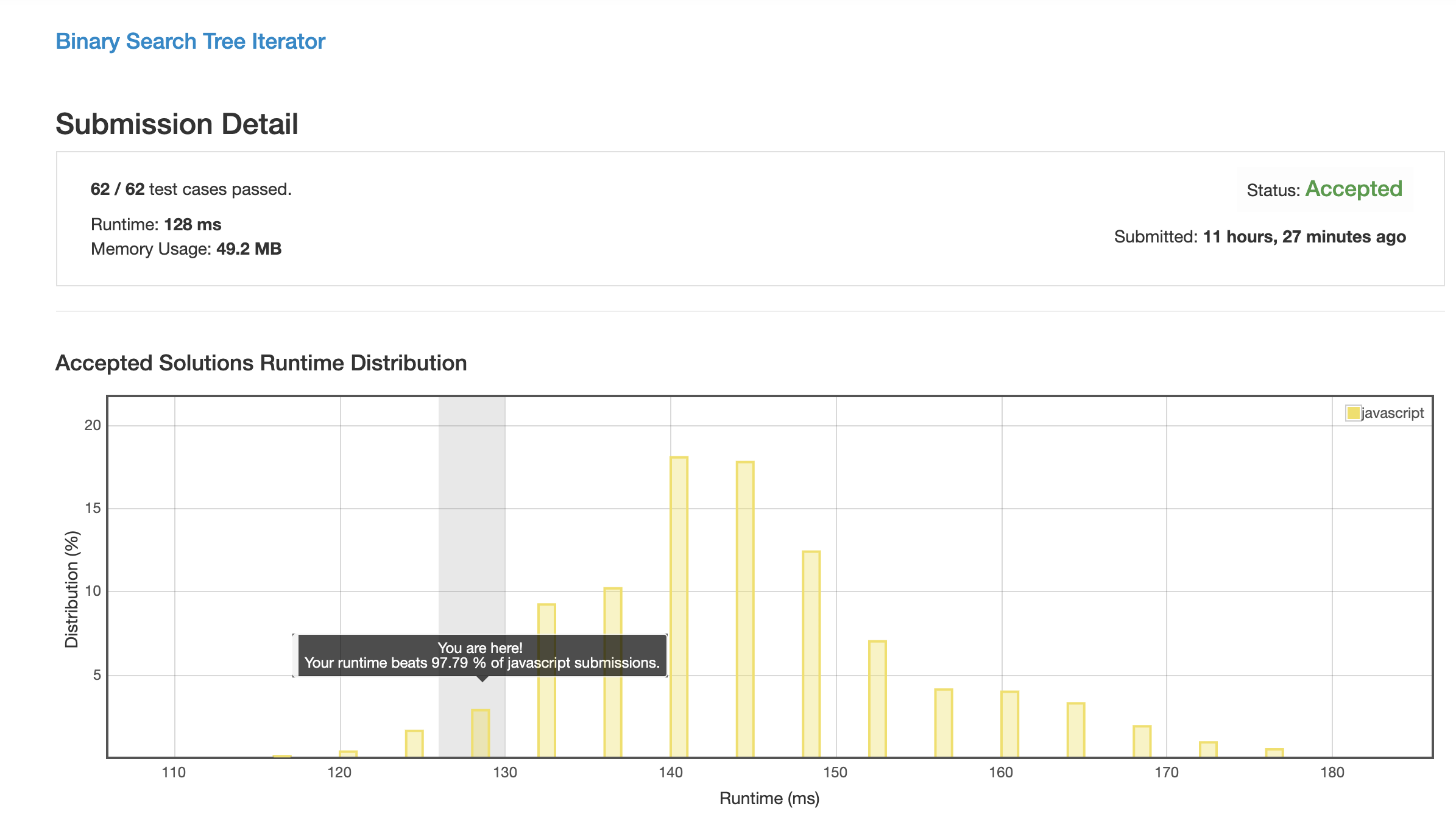
解法 1 (noob.js)
太简单了, 直接在构造函数里中序遍历并把结果缓存了, 后面 next 和 hasNext 的时候随用随取就 ok 了.
(而且这么做还因为不需要缓存额外结构而是个空间复杂度最优的解, 真的是太醉了
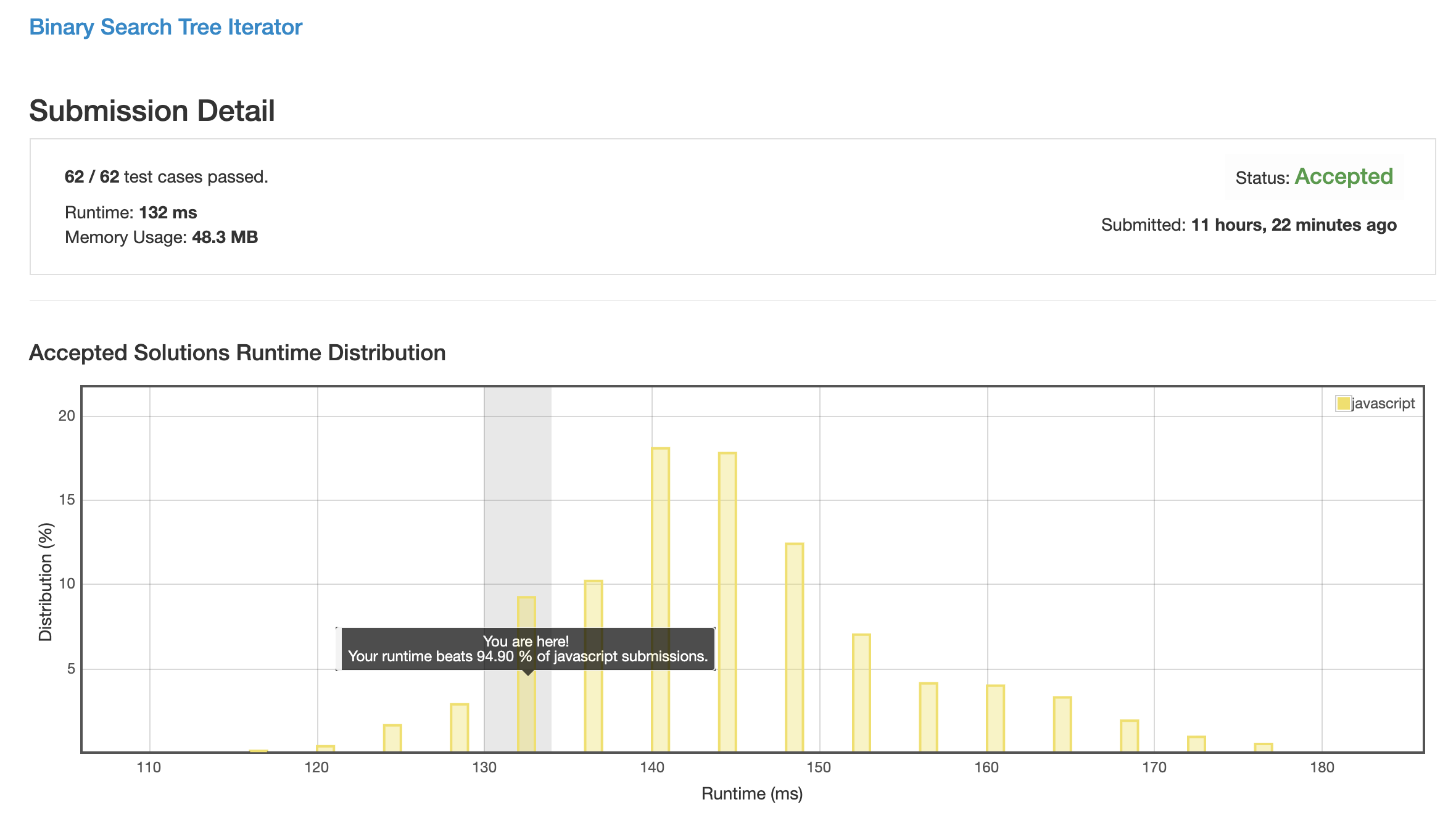
解法 2 (stack)
用堆栈来实现解递归 (其实堆栈实现解递归就是手动实现了一遍递归).
具体思路如下:
-
取 next 的时候如果结构未初始化, 则初始化, 具体过程为:
只要有 left 值, 就一直 push, 直到没有为止, 当前 stack 顶上的值就是本次 next 的结果 (整个树中最左侧的节点).
-
若已初始化, 则 pop 最顶上的节点 (该节点是上次被 next 函数把 val 值吐掉的节点)
判断该节点是否存在右子树:
-
若不存在, 则证明该节点为根的子树已遍历完成, 开始搞他的父级, 直接把父级的 val 返回回去, 下次再 next 的时候若他的父级有右子树, 就会进入下一个条件, 如果没有, 就会重复本条件.
-
若存在, 则把他的右子树从根开始不断 left 全部存入 (其实这里的 pop 节点, 就是上一步右子树不存在时被返回了 val 值的父级节点), 并把最后那个没有左子节点的节点的值返回回去 (模拟初始化流程).
-
这里就是模拟了中序遍历的过程:
-
在有 left 的时候不断深入调用, 直到没有为止.
-
然后把当前节点的值吐出去.
-
再然后对右子节点调用上述过程.
这里读完之后节点不吐出, 而在下一次遍历的时候吐出, 就是为了模拟出来递归体的行为逻辑:
function recursion(node) {
if (node.left) {
recursion(node.left);
}
node.val;
if (node.right) {
recursion(node.right);
}
}
模拟中序遍历不需要做状态判断标记, 只需要用堆栈压出足够的左子树队列就够了.
通过压光所有的左子树, 来模拟递归第一步的递归调用操作.
然后返回需要被处理的中序节点的数据.
最后再判断右子节点是否存在, 并再次进入下一个递归循环 (压左子树, 返回最后一个节点的值, 等待下次压入).
1. 使用堆栈不断积压左子树, 直到无左子树时, 就相当于 if (node.left) 判断失败, 运行到 node.val 这一步, 这时将结果返回回去.
1. 再进来的时候 pop 掉一层, 相当于执行完 node.val 的后半段操作, 需要处理的东西只剩父层和本层的右子节点了.
1. 这时判断右子节点是否存在:
~~ + 存在的话进入下一次递归操作, 会重复 步骤 1 的压栈操作, 并运行到 node.val 返回结果, 再回来时就是 步骤 2, 不再赘述.~~
~~ + 没有的话就相当于这个递归函数运行完了, 出去到上一层了, 继续上一层的逻辑.~~
1. 出去到上一层时并不需要关心上一级的状态, 因为如果是相当于到了上一层的 if (node.left) 后面 (因为左子树只要存在, 就会被 push 到数组中), 这时候返回结果 (相当于执行了 node.val), 然后继续将状态停在 node.val 后面.
优化点
因为数据不会动态改变, 所以我试了下初始化的时候直接构造数据, 看看能不能更快.
结果发现速度反而变慢了, 后来思考了下, 猜测应该是有很多节点并不会调用 next, 所以提前生成树是一个非常浪费的行为.
但上面的 noob 方法, 提前计算就比动态快 (因为动态计算增加了很多判断语句, 这些语句在 stack 方法中是必须的, stack 方法在有这些语句拖累的情况下比没有拖累的 noob 方法快, noob 方法再加上这些拖累的语句, 肯定就比 stack 慢了).